基于.NET的分词软件设计与实现V6.0--使用数据库篇
忙了一阵子,今天用空下来的一点时间来总结一下之前未完成的分词系列吧。。
上篇提到了使用HashSet<T>作为词典存储数据结构的方法,这也是在不使用数据库的情况下,自己在能力范围之内找到的最佳的解决方案。
但是,如果使用数据库呢,好吧,下面就让我们来看在使用数据库的情况下,本分词软件的表现。
一、建立数据库
在之前的版本中,分词的词典都以文本的形式直接保存在txt文件中,这里自然要将其全部转存到数据库的表中,介于词典采用的是每行存取一个词的方法,我采用的方法是循环读取文本文档的每一行,随后使用insert语句将其录入数据库的表中。
随后我们不作任何优化措施,直接开始简单的测试,首先开启SQL中显示统计信息和分析、编译、执行各语句耗时的功能:
SET STATISTICS IO ONSET STATISTICS TIME ON 来看一下查询“他们”这个简单的词,select * from Vocabulary where item = '他们'
SQL中的执行结果:

注意下面几个数据:逻辑读取871次,CPU时间=62毫秒,占用时间=59毫秒。
随后,我们将程序中判断某个词是否存在的程序改为:
/// <summary> /// Updated:判断是否在词典中出现 /// </summary> /// <param name="str"></param> /// <returns></returns> bool isExist(string str) { DBHelper db = new DBHelper(); return Convert.ToInt32(db.ExecuteScalar("select count(*) from Vocabulary where item = '" + str + "'")) > 0; }
起初我计划以1000字的文本测试,但最后发现这个想法很不现实,为什么?让我们看下100字文本的分词结果就知道了:
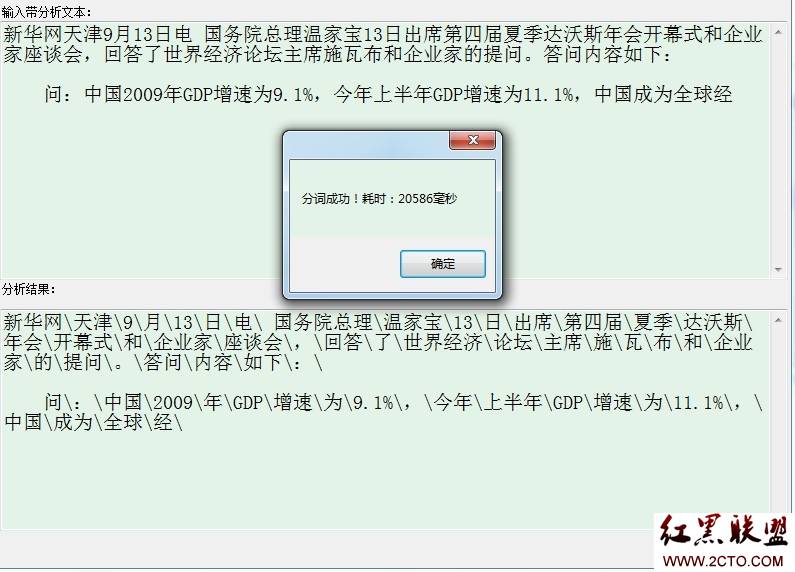
没错,100字的文本分词时间居然达到了20+秒,无法忍受的一个结果。
二、优化第一步——建立索引
索引的文章园子里面有很多,从原理到实例都有些经典的,这里自不必多说,这里主要看一下索引在本分词软件中的应用。
首先,我们频繁使用item字段,也就是保存词的字段进行查询,且其是表的主键,很适合建立聚集索引:
USE [Splitter]GO/****** 对象: Index [PK_Vocabulary] 脚本日期: 05/06/2011 23:56:26 ******/CREATE CLUSTERED INDEX [PK_Vocabulary] ON [dbo].[Vocabulary] ( [item] ASC)WITH ( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF) ON [PRIMARY] 好了,建立完成后来看一下最终的结果:

是不是看着顺眼多了(附加一句:py和len两个字段是我为了方便某些特殊查询,比如看有多少个拼音简写是ab的词等,在 程序中木有用处)。
下面以相同的语句查询“他们”这个词,看下结果:

注意下面几个数据:逻辑读取2次,CPU时间=0毫秒,占用时间=11毫秒。耗时明显大幅度降低了。
三、优化第二步——使用填充因子
填充因子百分比指首次创建索引时索引页的叶级别充满程序,若没有显示设置,则默认为0。
当最初生成索引时,SQL Server 将索引B 树结构放置在连续的物理页上,以便通过连续I/O 扫描索引页获取最佳I/O 性能。当由于发生页拆分,需要将新的页插入索引的逻辑B 树结构时,SQL Server 必须分配新的8 KB 索引页。这种插入发生在硬盘上的其它位置,从而打断了索引页的物理连续特性。使I/O 操作从连续变为不连续,从而使得性
相关新闻>>
- 发表评论
-
- 最新评论 进入详细评论页>>