浅谈如何屏蔽数据库中自增ID功能
在平时的项目开发中,我相信有很大一批人都在用这个数据库自增ID,用数据库自增ID有利也有弊。
优点:节省时间,根本不用考虑怎么来标识唯一记录,写程序也简单了,数据库帮我们维护着这一批ID号。
缺点:for example, 在做分布式数据库时,要求数据同步时,这种自增ID就会出现严重的问题,因为你无法用该ID来唯一标识记录。同时在数据库做移植时,也会出现各种问题,总之,对此自增ID有依赖的情况,都有可能出现问题。我绝对相信园子里有很一部分人都被这个“好用的东西” 曾经害惨过!
我平时在开发项目的时候,一般都没有用到数据库的自增ID, 所以我想分享一下自己的解决方法。
解决思路
1:定义一张表,专门用来存放存所有需要唯一ID的表名称以及该表当前所使用到的ID值。
2: 写一个存储过程,专门用来在上一步的表中取ID值。
这个思路非常简单,我不作解释了,直接来看看我的实现方法:
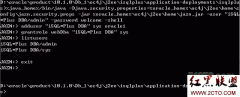
第一步:创建表
第二步:创建存储过程来取自增ID
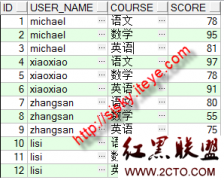
对于在表中不存在记录,直接返回一个默认值为1的键值,同时插入该条记录到table_key表中。而对于已存在的记录,key值直接在原来的key基础上加1.
总结一下,这种方法非常简单,我说一下它的优缺点。
优点:
1:ID值是可控的。用户可以从指定段开始分配ID值,这对于在分布式数据要求同数据同步时,非常方便,很好地解决了ID重复的问题。
2:在编写程序中,ID值是可见的,比如在再插入关联的记录时,相比使用数据库自增ID的情况下,这种方法不需要在插入一条数据库记录之后,再去得到自增ID值,然再再使用该ID的值来插入关联的记录。我们可以一次性使用事务来插入关联记录。
3:对于需要批量插入数据时,我们可以改写一下上面的存储过程,返回一个段的开始ID,然后更新表时需要注意,不是原来的简单的递增1,而是递增你想要的插入多少条记录的总数。
缺点:
1:效率问题,每次取ID值都需要调用存储过程从数据库中检索一次。对于这种情况,我觉得效率不是很大问题,因为SQL server 会对我们经常调用的存储过程有缓存,再一点,这个表的数据应该不会很大,最多上千条(一个项目中上千个表的情况应该不是很多吧)。所以检索不是什么问题,何况是根据表名来检索(表名列已是主键)。
相关新闻>>
- 发表评论
-
- 最新评论 进入详细评论页>>