SQL查询连续区间
这篇文章演示如何查询连续区间。
首先创建一个实验表,并插入测试数据。
1 create table tbl(num int not null primary key)
2 go
3
4 insert into tbl
5 values(1),(2),(3),(4),(5),(6),(100),(101),(102),(103),(104),(105),(200),(201),(202) -- 多值插入,SQL Server 2008新引入的语法。
6 go
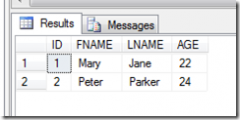
期望的结果是找出每一个连续区间的起始值和结束值,如下图:

如果能找到一个办法将每一个连续区间分成单独的组。那么,每个组中的最小值就是该区间的起始值,最大值就是该区间的结束值。当然,分组后还可以进行其它聚合计算。
从连续区间的定义可以得出一个结论:表中不存在比每个连续区间起始值小1的数字,也不存在比连续区间结束值大1的数字。反之,如果表中存在数字x并且不存在数字x-1,那么x就是起始值;如果表中存在数字y并且不存y+1,那么y就是结束值。
基于这个逻辑,可以得出一个计算每个数字所在区间起始值的方法:返回小于或等于当前数字的所有起始值中的最大者。同理,计算所在区间结束值的方法是:返回大于或等于当前数字的所有结束值中的最小者。
查询方案1:
1 select min(num) as start_num, max(num) as end_num
2 from
3 (select num,
4 (select MAX(num) from tbl as i where num <= o.num and not exists(select * from tbl where num = i.num - 1) ) as grp -- 计算所在组的起始值,作为分组号
5 from tbl as o) as m
6 group by grp
该查询的成本是:表扫描31次,逻辑读取281次,物理读取0次。
该查询为表中的每一行都计算了一次起始值,它的成本与表中的记录数成正比。以下查询为每个连续的区间只计算一次结束值,性能有很大提升。
查询方案2:
1 select num as start_num,
2 (select MIN(num) from tbl as a where num >= o.num and not exists (select * from tbl where num = a.num + 1)) as end_num
3 from tbl as o
4 where not exists(select * from tbl where num = o.num - 1)
该查询的成本是:表扫描8次,逻辑读取96次,物理读取0次。
表扫描从31次降到8次,逻辑读取也从281次降到了96次,性能有了明显的改善。该查询的成本与连续区间的数量成正比。
考虑到每次计算结束值都使用了min聚合函数,而且在num列上有索引。因此,可以使用top语句代替。以下是用top语句改进后的查询。
查询方案3:
1 select num as start_num,
2 (select top 1 num from tbl as a where num >= o.num and not exists (select * from tbl where num = a.num + 1) order by num) as end_num
3 from tbl as o
4 where not exists(select * from tbl where num = o.num - 1)
该查询的成本是:表扫描6次,逻辑读取70次,物理读取0次。
SQL Server 2005开始提供了row_number窗口函数,它用途广泛。
接下来介绍使用row_number函数解决连续区间问题的方案。
1 select min(num) as start_num, max(num) as end_num
2 from
3 (select num, num - ROW_NUMBER() over(order by num) as grp
4 from tbl) m
5 group by grp
该查询的成本是:表扫描1次,逻辑读取2次,物理读取0次。
相关新闻>>
- 发表评论
-
- 最新评论 进入详细评论页>>