有关SQL Server分布统计的问题
来源:未知 责任编辑:责任编辑 发表时间:2014-02-18 03:26 点击:次
最近常被一些人问到关于SQL Server中统计的问题,这些问题是:
是否需要关注数据库中统计的多少?
统计对象使用多个空间
就执行SQL语句来说,查询优化器使用索引或列的分布统计信息来选择最佳的策略或计划;如果缺少统计信息或统计信息过期,性能会受到影响。在回答这些问题前,需要介绍一些关于分布统计的背景知识:什么是分布统计、其重要性、如何创建、更新、显示或查询。
分布统计的定义
在介绍之前,不得不推荐的一些关于Holger Schmeling写的一系列关于统计的文章,强烈建议仔细阅读,我认为是最有价值的。
简单地说,统计(包含索引或列中的数据分布的一种映射或直方图)用于选取最好的查询执行计划;当系统正常时,你不必担心这些,这么说的原因是他们是自动创建的,随着数据的变化也保持自动更新,如果查询优化器‘编译’查询时,如果没有找到可用的统计来判断表或索引中的数据分布状态,数据库会在需要时自动创建一个,例如当你在WHERE子句中使用列过滤或在某列上进行DISTINCT操作时。
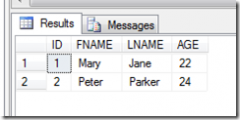
下面我们一起来看一下统计对象的直方图(Histogram),直方图主要衡量数据集中每一个非重复值的发生次数,查询优化器根据统计对象的第一个键列的值计算出一个直方图,通常一个直方图最多有200个值。
查看统计的详细信息,可以使用如下的命令:
1: DBCC SHOW_STATISTICS (Tab1, Stats_MyStatOnCol1)
执行结果如下:
 从上面的输出结果,注意到数据分成三个部分:Header、密度向量、Historgram。
从上面的输出结果,注意到数据分成三个部分:Header、密度向量、Historgram。在Header部分,由一系列有用的值(这些也可以结合STA_HEADER参数使用DBCC SHOW_STATISTICS来获取)下面介绍在Header中包含的信息:
名称 描述
Updated 记录更新统计的时间,也可以使用STATS_DATE函数获取
Rows 记录表或索引视图中总的行数
Rows Sampled 采样的行数,如果此条数小于总的记录数,显示的直方图和密度值则基于采样行数
Steps 直方图中的步值,每一个step表示一个范围值
Density 由1/非重复值(第一键列)算出
Average key Length 统计对象中键值的平均字节数
String Index 表示统计对象包含字符汇总统计以提高基数估计的性能,如WHERE ProductName like ‘%bike%'
Filter Expression NULL表示非filtered统计,有关filtered谓词,参阅Filtered Index Design Guidelines,有关filtered统计,参阅Using Statistics to Improve Quer performance.
Unfiltered Rows 应用Filter表达式前的表的行数,如果Filter Expression为空,则该值与Rows保持一致
对于密度向量,这里不进行介绍,查询优化器一般不使用此部分信息。
相关新闻>>
最新推荐更多>>>
- 发表评论
-
- 最新评论 进入详细评论页>>