SQL Server difference函数的近似值操作
来源:未知 责任编辑:责任编辑 发表时间:2014-02-02 17:50 点击:次
全名:搜索引擎算法的胡乱猜测 - SQL Server difference函数的近似值操作
最近正在对SQL Server所有内置函数进行一个通参(呵呵,自己造的词,其实就是从头到尾过一遍),进行到difference函数的时候简单的在IDE中进行了小小的尝试,目标代码如下:
最近正在对SQL Server所有内置函数进行一个通参(呵呵,自己造的词,其实就是从头到尾过一遍),进行到difference函数的时候简单的在IDE中进行了小小的尝试,目标代码如下:
1 declare @input nvarchar(100)='shenme'
2 declare @targetItem nvarchar(100)='ShenMa收藏'
3 select DIFFERENCE(@input,@targetItem)as result
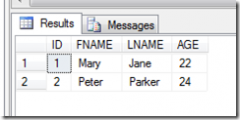
返回值如下:
result
-----------
4
(1 行受影响)
返回值为4,表明用户输入的值与进行比较的值是完全匹配的,但事实并不是这样'shenme'和'ShenMa收藏社区'明显是不一样的,只不过有几分相似而已,好,SQL Server中的相似值操作,就是我在这里要记录的(这句话换做大牛的说法是:好,这就是我们本节要讲的)。
difference返回值介绍:返回的整数是 SOUNDEX 值中相同字符的个数。返回的值从 0 到 4 不等:0 表示几乎不同或完全不同,4 表示几乎相同或完全相同。
首先需要讲明白的是,我要记录的是近似值操作,而并非类似四舍五入的操作:ROUND函数,他的作用是返回一个数值,舍入到指定的长度或精度。而我们这里要讨论的是: DIFFERENCE函数。
DIFFERENCE 返回一个整数值,指示两个字符表达式的 SOUNDEX 值之间的差异。
什么是SOUNDEX值?
SOUNDEX是一种语音算法,利用英文字的读音计算近似值,值由四个字符构成,第一个字符为英文字母,后三个为数字。在拼音文字中有时会有会念但不能拼出正确字的情形,可用Soundex做类似模糊匹配的效果。例如Knuth和Kant二个字符串,它们的Soundex值都是「K530」。
算法简要说明:
将英文字按以下规则替换(不使用第一个字符进行匹配):
a e h i o u w y -> 0
b f p v -> 1
c g j k q s x z -> 2
d t -> 3
l -> 4
m n -> 5
r -> 6
去除0,对于重复的字符只保留一个
返回前4个字符,不足4位以0补足
以Knuth和Kant为例:
Knuth -> K5030 -> K53 -> K530
Kant -> K053 -> K53 -> K530
不知道大家看明白了没有,我来简单说一下,比如目标字符串是Knuth,我们不使用第一个字符进行匹配,也就是不使用k,而将k作为匹配结果的第一个字符,所以第一个字符就得到了,他就是k,然后使用第二个字符进行匹配:n,n在以上匹配表中处于的位置是第六行,对应后边的数字为5,所以第二个匹配的字符也找到了,更新现在的结果字符串,就是k5,然后结合去除0,重复字符只保留一个等其他规则以此类推,就得到了最后的结果。
有人会问,这个difference函数有什么用,我要匹配相似结果的时候用like不就行了,是的,我们可以用like,但是试想一下这样的情况,我们在web应用程序的搜索栏中输入了“对比”两个字,搜索一下,发现结果为0,而数据库中却有一条名为:“比对“的记录,而且他们长的竟然那么像,所以实际情况中,我们是希望这样的数据能够被检索出来,以供用户浏览或处理的,所以这就是你经常使用的like关键字,我们可以复制一下代码,在MSSQLSERVER的IDE中运行一下,查看结果是不是跟我的执行结果一样。
相关新闻>>
最新推荐更多>>>
- 发表评论
-
- 最新评论 进入详细评论页>>