擦亮自己的眼睛去看SQLServer之简单Select
这篇文章主要和大家讨论几乎所有人都熟悉,但不少人又陌生的一条select语句。不知道大家有没有想过到底是什么东西让SQLServer能理解我们写的select。这中间到底发生了什么,是不是有过冲动想去了解。至少我曾经冲动想去了解,但当时主要在研究CLR以及webform相关知识。后来主要精力放在研究SQLserver内部机制,今天就给大家介绍下这条语句。
一、范例数据库脚本
create database Test
go
alter database Test set recovery simple
go
use Test
go
create table Test
(
ID int identity(1,1) primary key,
[Name] varchar(64) not null default ,
CreatedTime datetime not null default getdate()
)
insert into Test([name]) values(xiaojun)
这个脚本就不介绍了,很简单。
二、语句分析
select * from Test
简单吧,本来嘛标题就是之简单语句。下面开始分析这条语句吧,假设读者已经知道了SQLServer整体架构或者已经阅读过这个系列第一篇文章。当这条语句被可靠的传递到关系引擎中的命令分析器,接下来就发生了:
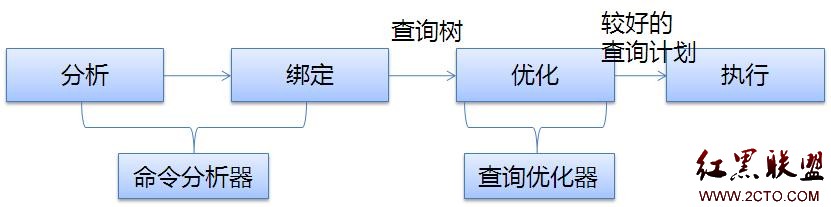
分析:从语法库中检查T-SQL进行基本的语法检查。如果语法出错了,那整个语句就立即停止,提示用户语法出错,哪出错。比如错误使用的关键字、列、表名等。如果语法没有出错,就会生成一个分析树传递给下一个步骤。
绑定:1、名字解析:检查所有的对象在用户的安全上下文中存在并可见。这个步骤很好理解主要是数据库每个对象都有权限。如果登录的账号没有相应权限,就结束这个步骤。
2、类型推导:确定解析树中每个节点的最终类型。这个步骤主要是补充分析分析步骤中的分析树,确定其最终的类型。不知道大家可想过为什么要到这一步才确定。为什么不在分析中确定呢?主要原因是效率,类型推导会消耗资源,没有必要在没有确定用户对每个对象有权限的情况下确定。那为什么不直接先确定用户对每个对象有权限再做分析呢。那是因为没做分析的时候,系统无法知道具体有哪些对象。我又要说了,SQLServer的设计真的可以说是很精致的,连这样的细节和资源消耗都考虑了。值得我们学习哦。
3、聚合绑定:确定哪些地方可以进行聚合。这个步骤主要和SQL中是否有聚合操作有关系。
4、组合绑定:将聚合绑定到正确的选择列表中。这个步骤是把聚合操作与需要聚合的列绑定对应起来。
这两步操作主要是由命令分析器完成,它最终得到分析树,传递给SQLServer引擎中最复杂最优技术含量的组件,没有之一,查询优化器。查询优化器功能概况起来很简单,就是优化SQL。具体优化模型如下:
优化:1、检查执行计划缓存中是有没对应的执行计划。 如果没有,继续下面操作。如果有则使用缓存。SQLServer是根据SQL的哈希值比较的。想想为什么?
2、预优化:查询语句很简单,开销足够小,直接结束优化。比如没有联接的基本查询。属于零开销,称为普通计划。比如我们这的select语句预优化就搞定了。
3、阶段0:检验基本规则,以及散列和嵌套联接选项。这个计划的开销是否小于0.2,如果是,结束优化。这里的0.2以及下面的1.0,这是SQLServer内部的开销值�
相关新闻>>
- 发表评论
-
- 最新评论 进入详细评论页>>