SQLServer通过DMV实现低影响的自动监控和历史场景追溯
一. 背景:
我们管理和维护的数据库系统基本都是7*24小时运转的,运转时会出现什么情况谁都无法估计,往往一个平时运行很正常的系统,某天晚上突然就抽风了,而此刻并没有系统负责人在旁边,当值班同事的电话打到正在酣睡的DBA手机上时,DBA不得不朦朦胧胧的,条件反射要上数据库看看;要在家里连到公司的内外一般都需要DBA通知运维人员(也可能是个在做梦的哥们)先给自己开个VPN(某些管控严格的公司还需要DBA打车去公司才能处理),然后通过一大堆的验证才通过慢如蜗牛(往往也和此刻的心态有关)的网络,远程连接到了公司内网出问题的数据库上,此刻DBA才开始真正开始排查起问题来;如果说等待DBA登录到问题数据库上,问题依然在出现,那还算好,可以很快找到问题并处理,但是往往这种抽风的现象是短暂的,可能持续几分钟后,系统又恢复了正常,等到DBA"跑山涉水,翻山越岭" 的好不容易登录到数据库上检查时,数据库里的进程、锁、日志一起都正常,系统运行的很Hai;于是第二天上班时老大们问起昨天晚上事故的原因时,DBA只能凭空猜测,可能是网络、数据库阻塞、抑或是程序方面的问题吧......,此刻不同部门的人都猜是其他部门管理的东西出了问题,于是大家都把手头上的数据、监控图拿出来,证明自己这里是没有问题的;如果监控网络和系统的图和APP的Log都没用出现啥问题(说实话监控也不一定准确的),那就基本要把问题推到数据库身上了(DBA往往成为炮灰)。
数据库有没有出问题,如果出了问题又是啥问题呢?windows Log和DB Log都没异常,如果我们没有把Profile持续的开启(基于性能的考虑,一般都不会持续开启),就很难说清楚在系统出问题时数据库究竟有没有出问题,出了问题又是因为什么原因引起的;如果说此类问题出现了一次,就消失了,那还算好,成为一个无头案,悲剧的是这类问题无规律,反复的出现,如果DBA不能找出问题的原因,也不能证明数据库当时是正常的话,估计在公司里面就没用立足之地了。
二. 对策:
其实对这种灵异的系统抽风事件,有两种比较好的解决方案:
1. 开启Trace 跟踪,就是数据库的Profile功能 ,这个还可以结合windows的性能计数器一同使用,能够直观的了解到特殊时间点上运行了什么语句,资源消耗情况是怎样的;不过这个方法比较消耗系统的资源,对访问压力比较大的数据库需要慎重;
2. 收集数据库DMV当时的情况,使得DBA在故障时间过后,还能通过这些数据了解到事故发生时,数据库里面运行的语句,以及锁和资源的情况;这种方法只是访问系统性能视图,对数据库其他业务影响比较小,也是我接下来要介绍的方案。
三. 实施方案:
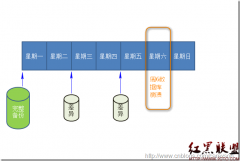
思路:根据数据库中某些动态指标,触发收集DMV的过程,必要时发送报警邮件
1. 创建存储系统性能视图的表:
--创建四个记录表
USE[master]
GO
/****** Object: Table [dbo].[dc_block_info] Script Date: 05/23/2011 11:35:48 ******/
SETANSI_NULLS ON
GO
SETQUOTED_IDENTIFIER ON
GO
SETANSI_PADDING ON
GO
CREATETABLE[dbo].[dc_block_info](
[spid][smallint]NULL,
[status][nchar](30) NULL,
[SQLBuffer][nvarchar](max) NULL,
[hostname][nchar](128) NULL,
[BlkBy][varchar](10) NULL,
[BlockedSQLBuffer][nvarchar](max) NULL,
[LoginName][varchar](100) NULL,
[DBName][varchar](50) NULL,
[CPUTime][int]NULL,
[DiskIO][int]NULL,
[LastBatch][datetime]NULL,
[program_name][nchar](128) NULL,
[Command][varchar](100) NULL,
[batch_id][int]NULL
) ON[PRIMARY]
GO
SETA
相关新闻>>
- 发表评论
-
- 最新评论 进入详细评论页>>