最近做了一次MySQL所谓的”海量数据”查询性能分析.
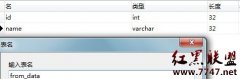
表结构
| dt |
dt2 |
dt3 |
it |
it2 |
it3 |
|
| id |
id |
id |
id |
id |
id |
int PK |
| |
|
ext1 |
|
|
ext1 |
varchar(256) |
| time |
time |
time |
time |
time |
time |
int/datetime KEY |
| |
ext2 |
ext2 |
|
ext2 |
ext2 |
varchar(128) |
说明, MyISAM引擎, dt表示时间字段使用datetime类型, it表示时间字段使用int类型.
初始数据
首先生成100K个UNIX时间戳(int), 然后随机选取10M次, 每一次往6个表里插入一条记录(当time字段是datetime类型时, 做类型转换). 所以每一个表都有10M条记录. ext1和ext2字段会用随机的字符串填充.
SQL查询
使用的查询SQL语句如:
select SQL_NO_CACHE count(*) from it where time>10000;
select SQL_NO_CACHE count(*) from dt where time>from_unixtime(10000);
select SQL_NO_CACHE * from it where time>10000 order by time limit 1;
select SQL_NO_CACHE * from it use key(PRIMARY) where time>10000 order by id limit 1;
SQL_NO_CACHE用于消除查询结果缓存的影响. use key用于指定查询时使用的索引. 统计每一条SQL的执行时间(单位s)和满足WHERE条件的记录总数(total), it-tm表示在dt表上执行SQL的耗时, 并explain得到key和extra, 结果如下.