jQuery源码分析-04 选择器-Sizzle-工作原理
作者:nuysoft/高云QQ:47214707 Email:nuysoft@gmail.com
声明:本文为原创文章,如需转载,请注明来源并保留原文链接。
在分析Sizzle源码之前,先整理一下选择器的工作原理
先明确选择器中用到的名词,后边阅读时不会有歧义:
选择器表达式:"div > p"
块表达式:"div" "p"
并列选择器表达式:"div, p"
块分割器:Sizzle中的chunker正则,对选择器表达式从左向右分割出一个个块表达式
查找器: 对块表达式进行查找,找到的DOM元素数组叫候选集
过滤器: 对块表达式和候选集进行过滤
关系过滤器: 对块表达式之间的关系进行过滤,共有四种关系:"+" 紧挨着的兄弟关系;">" 父子关系;"" 祖先关系;"~" 之后的所有兄弟关系
候选集: 查找器的结果,待过滤器进行过滤
映射集: 候选集的副本,过滤器和关系过滤器对映射集进行过滤
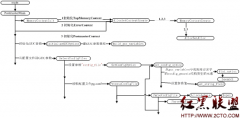
工作流程:
使用块分割器对选择器表达式进行分割,从左向右
如果遇到用逗号","分割的并列选择器表达式,只分割至第一个逗号前边的选择器表达式1,将剩余部分记录下来
对最后一个块表达式进行查找Sizzle.find,结果放入候选集set,并将块表达式中匹配的字符串部分删除
查找器Sizzle.find从正则集Expr.match获取对应的正则表达式,对块表达式进行匹配,匹配成功则从查找函数集Expr.find获取对应的查找函数执行
查找顺序定义在Expr.order中,依次是:ID CLASS NAME TAG,查找时CLASS需要浏览器支持getElementsByClassName
Expr.match中设定了ID CLASS NAME ATTR TAG CHILD POS PSEUDO的正则匹配表达式
如果最后一个块表达式不为空(字符串),过滤器Sizzle.filter对set进行过滤
过滤器Sizzle.filter仅对单个块表达式起作用,仅对候选集set中的元素起作用,检查候选集set中的元素满足剩余的块表达式
在过滤器Sizzle.filter的过滤过程中,不符合条件的被设置为false,符合条件的不做修改
过滤时从正则集Expr.leftMatch获取对应的正则表达式,对块表达式进行匹配,匹配成功则从Expr.filter获取对应的过滤函数执行
Expr.leftMatch定义了与Expr.match同样数量的正则表达式:ID CLASS NAME ATTR TAG CHILD POS PSEUDO
过滤函数集Expr.filter定义了PSEUDO CHILD ID TAG CLASS ATTR POS的过滤函数
过滤器Sizzle.filter进行过滤之前,会先调用预过滤器Expr.preFilter对过滤所需的参数进行修正,但是CLASS是个例外
在CLASS进行预过滤时做了优化,直接将匹配class的元素作为候选集返回,缩小过滤范围,缩小候选集范围
将以上查找和过滤得到候选集set复制,放入映射集checkSet,后边的过滤操作在checkSet上进行
对最后一个块表达式的查找和过滤到这里结束,得到一个候选集set和映射集checkSet
在映射集checkSet上将剩余的块表达式从右向左进行过滤,根据与前一个块表达式的关系,从关系过滤器集Expr.relative中获取对应的函数执行关系过滤
在关系过滤器Expr.relative的过滤过程中,不符合条件的被设置为false,符合条件的则被设置为父元素、祖先元素、兄长元素
元素之间的关系共有四种:"+" 紧挨着的兄弟关系;">" 父子关系;"" 祖先关系;"~" 之后的所有兄弟关系
在关系过滤器Expr.relative的过滤过程中,如果遇到块表达式是标签TAG的情况,则直接比较标签类型nodeName是否相等
如果不是标签TAG的情况,则会调用过滤器Sizzle.filter进行过滤,过滤过程见第3步
从右向左过滤,直到所有块表达式全部过滤完
根据过滤后的映射集checkSet,从候选集set中挑选最终的结果集,在映射集checkSet中
如果是null、false,将被过滤
如果不是Element(nodeType===1),将被过滤
如果上下文不是Document而是某个Element,不是Element的子元素的,将被过滤
如果存在并列表达式,重复1~5,并将得到的最终结果集合并、排序、去重
如果仅有一个选择器表达式,没有并列选择器表达式,不需要排序
以下过程不属于Sizzle,属于jQuery对Sizzle的扩展
如果存在多�
相关新闻>>

- 发表评论
-
- 最新评论 进入详细评论页>>